PMPC-exemple de configuration de poste travail
Praat, Matching Pursuit, Complearn
auteur : Guilleminot, C.
La configuration
La structure de répertoires proposée ici est une étude de cas qui permet d'utiliser PMPC le plus simplement possible. Nous ne changerons pas la configuration de base de PMPC et vous devrez l'adapter à chacun de vos projets.

Notre corpus
Ce corpus concerne quatre zones linguistiques arabophones et nous avons obtenus les productions de quatre locuteurs par zone. Pour chaque zone nous nous intéressons à l'arabe standard contemporrain et à l'arabe populaire, ce qui donne 32 enregistrements pour les 16 locuteurs. Chaque enregistrement contient 24 phrases répétées trois fois. Nous nous proposons de comparer diverses structures VCV.
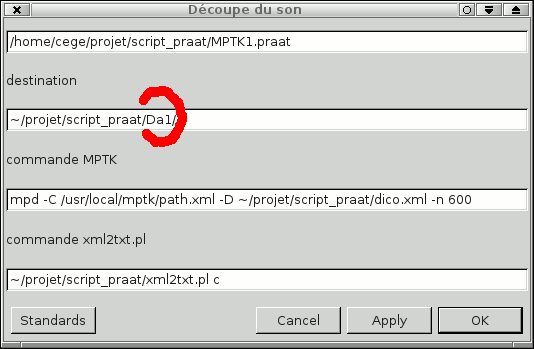
Organisation des répertoires
Il est inutile de créer une structure de répertoires avant de commencer. Nous utiliserons la possiblité de donner un nom à chaque destination dans la fenêtre du script PMPC dans Praat. Dans l'exemple présent se sera ja1, ja2...., ja4, ka1, ka2..., ka4, ya1, ya2..., Da1, Da2..., etc..
Résumé
- importer le script MPTK1.praat dans Praat ;
- charger le fichier sonore (.wav) et la TextGrid correspondante ;
- donner un nom au répertoire du locuteur dans la fenêtre du script PMPC ;
- lancer le script, les résultats sont placés dans le répertoire voulu
- revenir au point 2 pour le deuxième locuteur et ainsi de suite.
À la fin, nous devons avoir une structure ressemblant au schéma ci-dessous :

Traitement des fichiers
Les fichiers qui nous intéressent se trouvent dans des répertoires "résultat", pour ja1, ce sera /home/mon_répertoire/projet/ja1/xml/resultat/. Le répertoire « resultat » contient des fichiers texte (de type csv) qui peuvent être chargés dans un tableur comme Opencalc ou Gnumeric. Il est toutefois préférable d'utiliser encore une fois des scripts qui modifieront tous les fichiers séquentiellement en limitant les risques d'erreur et placeront ceux qui nous intéressent dans un répertoire de travail choisi. Ces scripts agiront dans les différents répertoires en effectuants certaines opérations de simplification des fichiers et la mise en place des données pour les expériences prévues.
Calcul des matrices de distance et production des graphes
Cette étape consiste à traiter le répertoire de travail avec Complearn et à générer les graphes de résultats. Elle variera légèrement en fonction des logiciels de compression choisis
Après de nombreux tests, j'ai choisi le compresseur paq8jd64 (64, parce que j'ai un processeur de 64 bits). Ce compresseur créé normalement des archives ce qui n'est pas le but recherché. Le script utilisé doit l'appliquer individuellement sur chaque fichiers. Certains compresseur ne créent pas d'achives et compressent individuellement en une seule commande tous les fichiers d'un répertoire. J'ai choisi paq8jd64 (version 64 bits) parce qu'il donnait le meilleur taux de compression sans user d'un dictionnaire extérieur. Lire Matt Mahoney
Une fois le ou les répertoires de données construits, il suffit d'appliquer les commandes Complearn puis Graphviz.
Calcul de la matrice de distance
ncd -b -d ./example ./example > distmatrix.clb
Note : il faut répéter deux fois le répertoire de données (ici ./exemple) parce que la matrice de départ à les mêmes éléments pour les lignes et les colonnes.
Optimisation de la matrice obtenue
maketree distmatrix.clb
Cette commande génère un fichier treefile.dot.
Génération du graphe
neato -Tsvg -Gsize=2000 treefile.dot > tree.svg
Ici on obtient une image au format vectoriel .svg.
Note : ces trois commandes peuvent être regroupées en une seule commande shell.
Changer l'extension des fichiers d'un répertoire
Il est probable que les noms des noeuds des graphes ne soient pas satisfaisants. Des commandes simples permettent de résoudre ces problèmes.
Changer une extension pour une autre :
rename 's/\.[^\.]+$/\nouvelle/' *
Supprimer l'extension des fichiers d'un répertoire :
rename 's/\.[^\.]+$//' *
Dans certains cas on utilisera plutôt des commandes Perl, shell, awk...